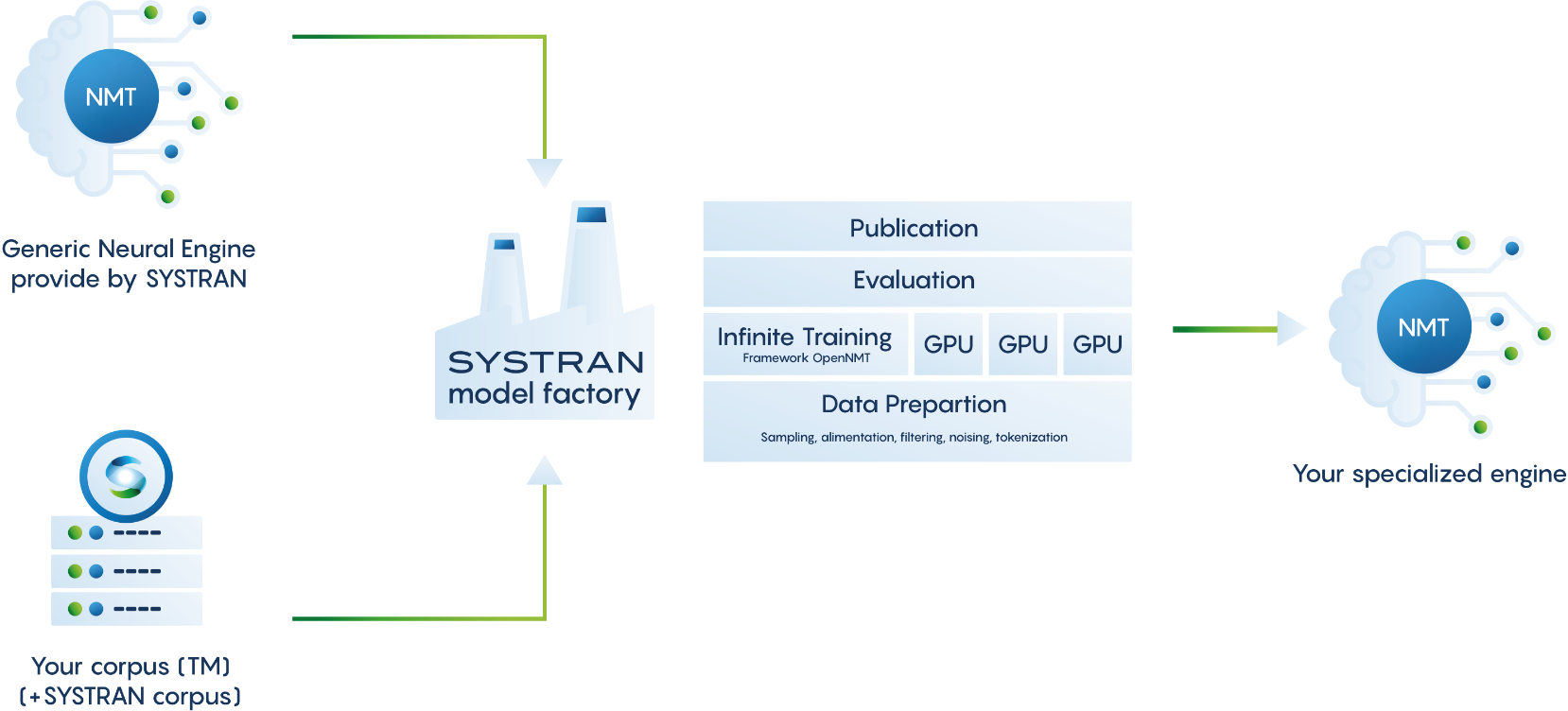
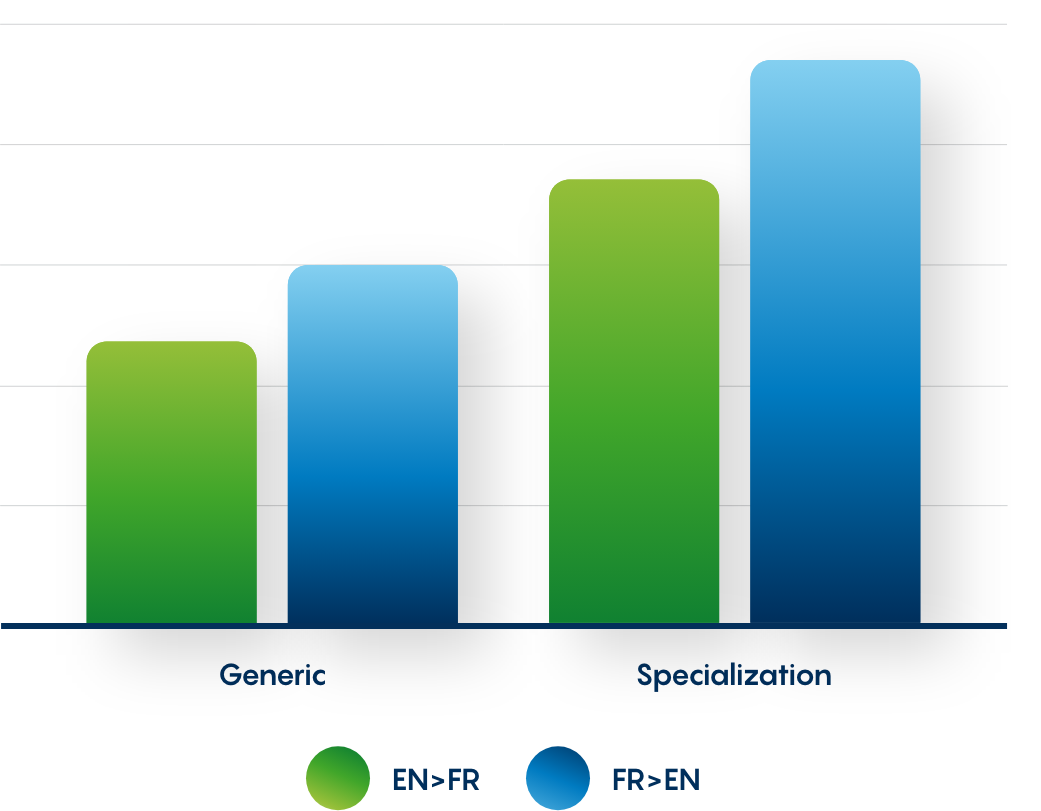
Achieve greater accuracy with SYSTRAN domain-specific engines and specialized translation models. Translation models can be built based on your existing corpus (bilingual or monolingual text). If your company doesn't have enough data, we can provide access to our own Corpus Factory, a substantial internal database encompassing monolingual and bilingual text with free or purchased intellectual property rights.

 UBICATION
UBICATION
 UBICATION
UBICATION
 UBICATION
UBICATION
 UBICATION
UBICATION
 UBICATION
UBICATION
 UBICATION
UBICATION